Part 2 of a 2-part post on the FTS features available in Postgres and how you might use them to build a simple search API. If you want to follow along head over to the GitHub repo, grab the source data and spin up the included docker config, we'll be searching a database of 50,000 movies. Check out part 1 and the accompanying GitHub repository.
Searching multiple columns
Now what if we want to search across multiple columns, for example our database has an original_title and a title column for each movie. We can concatenate each column tsvector so we have one tsvector to search.
select to_tsvector(title) || ' ' || to_tsvector(original_title)
from movies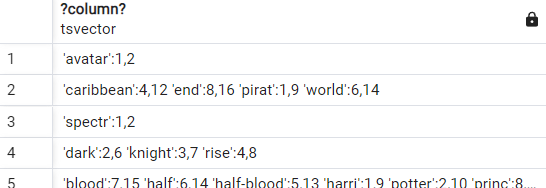
But what if I want to prioritise search results in certain columns, for example I want matches in title to be ranked higher than original_title. Of course, Postgres has this covered with the setweight function which we can use to weight the results of any tsvector from A, the highest weighted, to D, the lowest.
select setweight(to_tsvector(title), 'A') || ' ' || setweight(to_tsvector(original_title), 'B')
from movies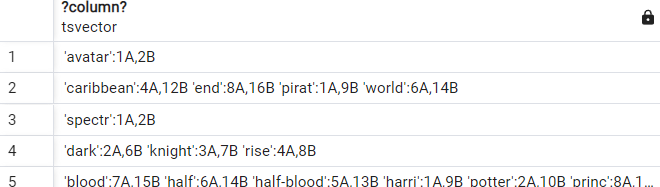
Make querying easier
Now we can, for example, search for the movie Hero by its original title.
select title, original_title,
ts_rank(to_tsvector(title) || ' ' || to_tsvector(original_title), websearch_to_tsquery('英雄')) as rank
from movies
where to_tsvector(title) || ' ' || to_tsvector(original_title)
@@ websearch_to_tsquery('英雄')
order by rank desc 
This is pretty powerful, but our SQL is starting to get a bit cumbersome, and it would be nicer, and more performant, if we didn't have to build our vectors for every query. We could create a tsvector column on the table and store the weighted vectors and then use triggers to keep that column updated on any change to the table data. Yuck... 🤢
So instead let's take advantage of another awesome Postgres feature Generated Columns.
A generated column is a special column that is always computed from other columns. Thus, it is for columns what a view is for tables.
alter table movies
add title_search tsvector
generated always as (
setweight(to_tsvector('simple', coalesce(title, '')), 'A') || ' ' ||
setweight(to_tsvector('simple', coalesce(original_title, '')), 'B') :: tsvector
) stored; We've changed the way we call to_tsvector slightly here because our generated column must be immutable so we use coalesce to make sure any null values will be represented as an empty string, and we also specify that we're using the 'simple' text search configuration (more on that in just a moment).
For now, let's just enjoy how quick and easy it is to query our weighted vectors.
select title, original_title, ts_rank(title_search, websearch_to_tsquery('hero')) as rank
from movies
where title_search @@ websearch_to_tsquery('hero')
order by rank desc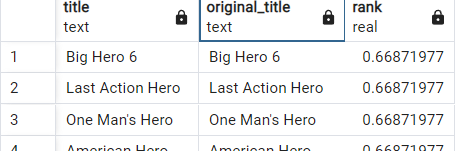
A brief discussion of Text Search Configuration
A text search configuration specifies all options necessary to transform a document into a tsvectorWe can see a list of the available Text Search Configurations (TSC) for our Postgres instance by querying pg_ts_config.
SELECT * FROM pg_ts_config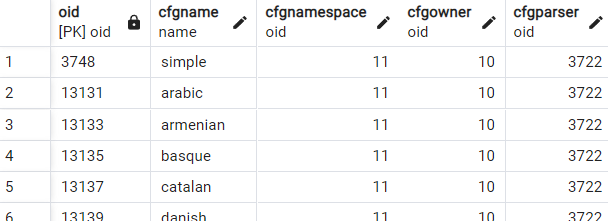
The TSCs available by defaults are each focused on a language and are configured to use a language specific dictionary. So far, we have always used the simple TSC when calling to_tsvector and *to_tsquery. This TSC 'simply' converts the input tokens to lower case and discards common stop words.
select to_tsvector('simple', 'To fish the fishes a fishy fisher fished')
If we use a language specific TSC (english) instead then many more, English, stop words are discarded and each word is normalized so that, for example, the plural of fishes would be normalized to fish.
select to_tsvector('english', 'To fish the fishes a fishy fisher fished')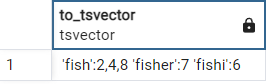
This has many benefits, first it saves space because fewer normalized values (lexemes) are stored. Second by normalizing words to lexemes based on the dictionary we are able to take advantage of stemming so that, for example, a search for fishes would match with fish, fishes, fished. Thirdly it means that all of this can be done in a way that supports whichever language our documents may be stored and searched in.
You can customize TSCs or build your own to support synonyms, thesauruses and much more, I'd highly recommend reading the Text Search Configuration documentation if you'd like to learn more.
Will it index?
OK back to searching our movie database and at this point we need to start thinking about performance. Our database only contains a few thousand records, so our query timings are all measured in milliseconds. But what would happen if we were querying hundreds of thousands or millions of rows? Put simply, performance would suck because right now we're doing a sequential scan for every query which requires iterating through every row of the table. If we analyse our query, we can see a clear warning about this.

If only Postgres had some kind of special index designed for speeding up full text search that would be awesome, and of course it does ... GIN indexes.
create index idx_search on movies using GIN(title_search)
You can see the huge reduction in the Timings above, we've gone from around 7.5 ms to less than 0.04 ms, and at this point we have a search query that can be fast enough for a real production environment.
Addendum
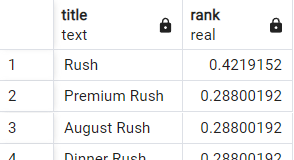
Just one more thing before we're done. Intuitively if I was to run a title search for 'rush' I would expect the highest ranked result to be the movie with the title 'Rush' but, by default, the ts_rank function doesn't consider document or query length.
select title, ts_rank(title_search, websearch_to_tsquery('rush')) as rank
from movies
where title_search @@ websearch_to_tsquery('rush')
order by rank desc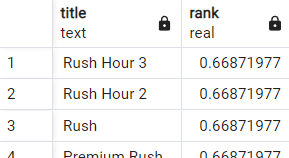
If we pass a normalization option to ts_rank we can specify how the document's length should impact its rank and make our results more intuitive.
select title, ts_rank(title_search, websearch_to_tsquery('rush'), 1) as rank
from movies
where title_search @@ websearch_to_tsquery('rush')
order by rank desc