
Everyone needs Full Text Search (FTS) at some point and the most common way to get it is to push your data to Elastic/OpenSearch, Solr, or something else built on top of Lucene. It's a solution that works but adds extra complexity, cost, and consistency challenges. So, what if I told you that, if you're using PostgreSQL, powerful FTS is available to you out of the box?
Play along
If you want to follow along head over to the GitHub repo and spin up the docker file and included source data.
 admcpr
admcprPostgres text search the wrong way️
We're going to build the SQL for a hypothetical API endpoint that searches movies. Let's start by trying to search for a well-known film by its title the wrong way™️. We can use like to do basic pattern matching so a simple solution might be to split the search input into individual words and wrap them with %.
select title from movies where title like '%star%' or title like '%wars%' 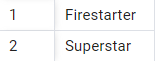
Two results, but not Star Wars though because of course I've forgotten that like is case sensitive.
select title from assets where title ilike '%star%' or title ilike '%wars%' 
Now I get 36 results and Star Wars is in there, but the basic pattern matching provided by ilike doesn't rank our results and is never going to help us with more complicated concepts like stemming.
Help me tsvector you are my only hope
So enough of what won't work let's look at some tools that will. We're going to start with tsvector which, to quote the Postgres documentation:
A tsvector value is a sorted list of distinct lexemes, which are words that have been normalized to merge different variants of the same word.We can use the to_tsvector function to parse text and turn into a tsvector for us.
select to_tsvector('I am altering the deal. Pray I don''t alter it any further!');
Now let's do that to some of our movie titles.
select title, to_tsvector(title) from movies limit 20;
Now we can use the to_tsquery function to query the tsvector of the title instead of querying the title directly. Let's start simple.
select title
from movies
where to_tsvector(title) @@ to_tsquery('Star')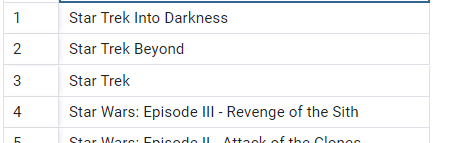
It would be nice if we could order the results by how well they match our query so let's use the ts_rank function to return a value for that.
select title, ts_rank(to_tsvector(title), to_tsquery('Star')) as rank
from assets
where to_tsvector(title) @@ to_tsquery('star')
So, let's find Star Wars.
select title, ts_rank(to_tsvector(title), to_tsquery('star wars')) as rank
from movies
where to_tsvector(title) @@ to_tsquery('star wars') 
Oh, come on! It was all going so well but a restriction of tsquery is that it:
must consist of single tokens separated by thetsqueryoperators&(AND),|(OR),!(NOT), and<->(FOLLOWED BY)
In short, no spaces allowed. We could fix this simply by changing 'star wars' to 'star<->wars' but then if we were, for example, building a search API endpoint we'd need to parse the input, split and rejoin it. Instead let's just use plainto_tsquery which will generate a tsquery from plain text and now we can find Star Wars 🎉
select title, ts_rank(to_tsvector(title), plainto_tsquery('star wars')) as rank
from movies
where to_tsvector(title) @@ plainto_tsquery('star wars')
order by rank desc
More powerful search syntax
As tsquery supports operators it would be nice to expose this functionality via our API so that a user could execute more complicated searches. We could either expect our users to learn the tsquery syntax or we could parse the incoming query and build a valid tsquery for them. Fortunately, though we don't have to do either of those because the websearch_to_tsquery function lets us support the following popular syntax for free.
"quoted text": text inside quote marks will be converted to terms separated by<->operators. Also, stop words are not simply discarded, but are accounted for by inserting<N>operators rather than<->operators.OR: the word “or” will be converted to the|operator.+: a plus will be converted to the&operator.-: a dash will be converted to the!operator.
For example, select websearch_to_tsquery('"star wars" -clone') would give us a query of 'star'<->'war'&!clone' to search for results that include Star Wars but exclude Clone. Or if the user was only interested in Star Wars movies about Clones.
select title, ts_rank(to_tsvector(title), websearch_to_tsquery('"star wars" +clone')) as rank
from movies
where to_tsvector(title) @@ websearch_to_tsquery('"star wars" +clone')
order by rank desc 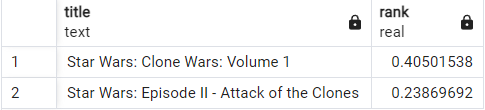
Part 2
In the second, and final, part of this post we cover searching multiple columns, simpler queries, performance and more.
